Kappa
“Great things are not done by impulse, but by a series of small things brought together.”
Hack The Box
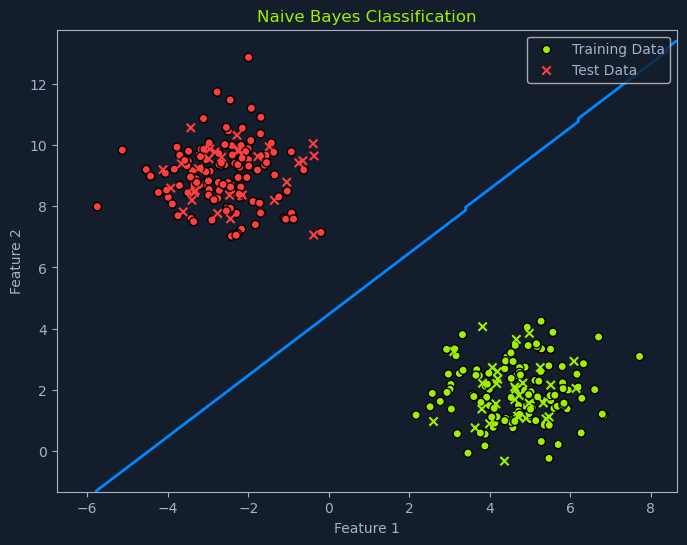
Naive Bayes
Naive Bayes is a probabilistic algorithm used for classification tasks. It's based on Bayes' theorem, a fundamental concept in probability theory that describes the probability of an event based on prior knowledge and observed evidence. Naive Bayes is a popular choice for tasks like spam filtering and sentiment analysis due to its simplicity, efficiency, and surprisingly good performance in many real-world scenarios.
{kind=link}
Bayes' Theorem
Before diving into Naive Bayes, let's understand its core concept: Bayes' theorem. This theorem provides a way to update our beliefs about an event based on new evidence. It allows us to calculate the probability of an event, given that another event has already occurred.
It's mathematically represented as:
P(A|B) = [P(B|A) * P(A)] / P(B)
Where:
P(A|B): The posterior probability of event A happening, given that event B has already happened.
P(B|A): The likelihood of event B happening given that event A has already happened.
P(A): The prior probability of event A happening.
P(B): The prior probability of event B happening.
Let's say we want to know the probability of someone having a disease (A) given that they tested positive for it (B). Bayes' theorem allows us to calculate this probability using the prior probability of having the disease (P(A)), the likelihood of testing positive given that the person has the disease (P(B|A)), and the overall probability of testing positive (P(B)).
Suppose we have the following information:
- The prevalence of the disease in the population is 1%, so P(A) = 0.01.
- The test is 95% accurate, meaning if someone has the disease, they will test positive 95% of the time, so P(B|A) = 0.95.
- The test has a false positive rate of 5%, meaning if someone does not have the disease, they will test positive 5% of the time.
- The probability of testing positive, P(B), can be calculated using the law of total probability.
First, let's calculate P(B):
P(B) = P(B|A) * P(A) + P(B|¬A) * P(¬A)
Where:
P(¬A): The probability of not having the disease, which is 1 - P(A) = 0.99.
P(B|¬A): The probability of testing positive given that the person does not have the disease, which is the false positive rate, 0.05.
Now, substitute the values:
P(B) = (0.95 * 0.01) + (0.05 * 0.99)
= 0.0095 + 0.0495
= 0.059
Next, we use Bayes' theorem to find P(A|B):
P(A|B) = [P(B|A) * P(A)] / P(B)
= (0.95 * 0.01) / 0.059
= 0.0095 / 0.059
≈ 0.161
So, the probability of someone having the disease, given that they tested positive, is approximately 16.1%.
This example demonstrates how Bayes' theorem can be used to update our beliefs about the likelihood of an event based on new evidence. In this case, even though the test is quite accurate, the low prevalence of the disease means that a positive test result still has a relatively low probability of indicating the actual presence of the disease.
How Naive Bayes Works
The Naive Bayes classifier leverages Bayes' theorem to predict the probability of a data point belonging to a particular class given its features. To do this, it makes the "naive" assumption of conditional independence among the features. This means it assumes that the presence or absence of one feature doesn't affect the presence or absence of any other feature, given that we know the class label.
Let's break down how this works in practice:
- Calculate Prior Probabilities: - The algorithm first calculates the prior probability of each class. This is the probability of a data point belonging to a particular class before considering its features. For example, in a spam detection scenario, the probability of an email being spam might be 0.2 (20%), while the probability of it being not spam is 0.8 (80%).
- Calculate Likelihoods: - Next, the algorithm calculates the likelihood of observing each feature given each class. This involves determining the probability of seeing a particular feature value given that the data point belongs to a specific class. For instance, what's the likelihood of seeing the word "free" in an email given that it's spam? What's the likelihood of seeing the word "meeting" given that it's not spam?
- Apply Bayes' Theorem: - For a new data point, the algorithm combines the prior probabilities and likelihoods using Bayes' theorem to calculate the posterior probability of the data point belonging to each class. The posterior probability is the updated probability of an event (in this case, the data point belonging to a certain class) after considering new information (the observed features). This represents the revised belief about the class label after considering the observed features.
- Predict the Class: - Finally, the algorithm assigns the data point to the class with the highest posterior probability.
While this assumption of feature independence is often violated in real-world data (words like "free" and "viagra" might indeed co-occur more often in spam), Naive Bayes often performs surprisingly well in practice.
Types of Naive Bayes Classifiers
The specific implementation of Naive Bayes depends on the type of features and their assumed distribution:
- Gaussian Naive Bayes: - This is used when the features are continuous and assumed to follow a Gaussian distribution (a bell curve). For example, if predicting whether a customer will purchase a product based on their age and income, Gaussian Naive Bayes could be used, assuming age and income are normally distributed.
- Multinomial Naive Bayes: - This is suitable for discrete features and is often used in text classification. For instance, in spam filtering, the frequency of words like "free" or "money" might be the features, and Multinomial Naive Bayes would model the probability of these words appearing in spam and non-spam emails.
- Bernoulli Naive Bayes: - This type is employed for binary features, where the feature is either present or absent. In document classification, a feature could be whether a specific word is present in the document. Bernoulli Naive Bayes would model the probability of this presence or absence for each class.
The choice of which type of Naive Bayes to use depends on the nature of the data and the specific problem being addressed.
Data Assumptions
While Naive Bayes is relatively robust, it's helpful to be aware of some data assumptions:
- Feature Independence: - As discussed, the core assumption is that features are conditionally independent given the class.
- Data Distribution: - The choice of Naive Bayes classifier (Gaussian, Multinomial, Bernoulli) depends on the assumed distribution of the features.
- Sufficient Training Data: - Although Naive Bayes can work with limited data, it is important to have sufficient data to estimate probabilities accurately.