Kappa
“Great things are not done by impulse, but by a series of small things brought together.”
Hack The Box
Support Vector Machines (SVMs)
Support Vector Machines (SVMs) are powerful supervised learning algorithms for classification and regression tasks. They are particularly effective in handling high-dimensional data and complex non-linear relationships between features and the target variable. SVMs aim to find the optimal hyperplane that maximally separates different classes or fits the data for regression.
{kind=link}
Maximizing the Margin
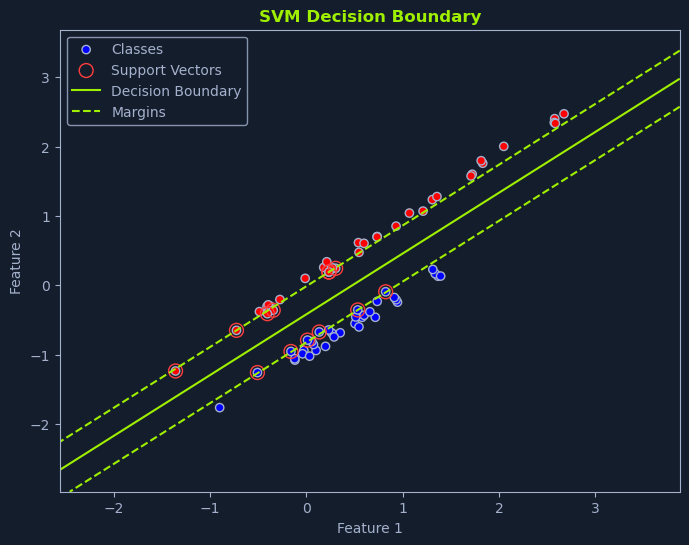
An SVM aims to find the hyperplane that maximizes the margin. The margin is the distance between the hyperplane and the nearest data points of each class. These nearest data points are called support vectors and are crucial in defining the hyperplane and the margin.
By maximizing the margin, SVMs aim to find a robust decision boundary that generalizes well to new, unseen data. A larger margin provides more separation between the classes, reducing the risk of misclassification.
Linear SVM
A linear SVM is used when the data is linearly separable, meaning a straight line or hyperplane can perfectly separate the classes. The goal is to find the optimal hyperplane that maximizes the margin while correctly classifying all the training data points.
Finding the Optimal Hyperplane
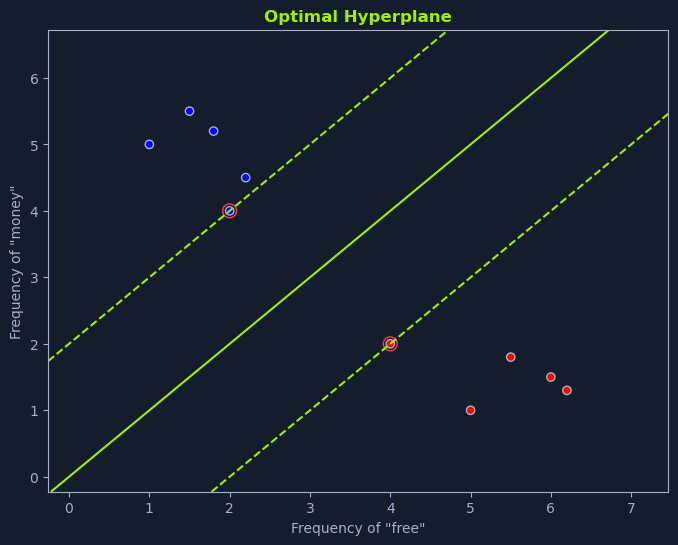
Imagine you're tasked with classifying emails as spam or not spam based on the frequency of the words "free" and "money." If we plot each email on a graph where the x-axis represents the frequency of "free" and the y-axis represents the frequency of "money," we can visualize how SVMs work.
{kind=link}
The optimal hyperplane is the one that maximizes the margin between the closest data points of different classes. This margin is called the separating hyperplane. The data points closest to the hyperplane are called support vectors, as they "support" or define the hyperplane and the margin.
Maximizing the margin is intended to create a robust classifier. A larger margin allows the SVM to tolerate some noise or variability in the data without misclassifying points. It also improves the model's generalization ability, making it more likely to perform well on unseen data.
In the spam classification scenario depicted in the graph, the linear SVM identifies the line that maximizes the distance between the nearest spam and non-spam emails. This line serves as the decision boundary for classifying new emails. Emails falling on one side of the line are classified as spam, while those on the other side are classified as not spam.
The hyperplane is defined by an equation of the form:
w * x + b = 0
Where:
w is the weight vector, perpendicular to the hyperplane.
x is the input feature vector.
b is the bias term, which shifts the hyperplane relative to the origin.
The SVM algorithm learns the optimal values for w and b during the training process.
Non-Linear SVM
In many real-world scenarios, data is not linearly separable. This means we cannot draw a straight line or hyperplane to perfectly separate the different classes. In these cases, non-linear SVMs come to the rescue.
{kind=link}
Kernel Trick
Non-linear SVMs utilize a technique called the kernel trick. This involves using a kernel function to map the original data points into a higher-dimensional space where they become linearly separable.
Imagine separating a mixture of red and blue marbles on a table. If the marbles are mixed in a complex pattern, you might be unable to draw a straight line to separate them. However, if you could lift some marbles off the table (into a higher dimension), you might be able to find a plane that separates them.
This is essentially what a kernel function does. It transforms the data into a higher-dimensional space where a linear hyperplane can be found. This hyperplane corresponds to a non-linear decision boundary when mapped back to the original space.
Kernel Functions
Several kernel functions are commonly used in non-linear SVMs:
- Polynomial Kernel: - This kernel introduces polynomial terms (like x², x³, etc.) to capture non-linear relationships between features. It's like adding curves to the decision boundary.
- Radial Basis Function (RBF) Kernel: - This kernel uses a Gaussian function to map data points to a higher-dimensional space. It's one of the most popular and versatile kernel functions, capable of capturing complex non-linear patterns.
- Sigmoid Kernel: - This kernel is similar to the sigmoid function used in logistic regression. It introduces non-linearity by mapping the data points to a space with a sigmoid-shaped decision boundary.
The kernel function choice depends on the data's nature and the model's desired complexity.
Image Classification
Non-linear SVMs are particularly useful in applications like image classification. Images often have complex patterns that linear boundaries cannot separate.
For instance, imagine classifying images of cats and dogs. The features might be things like fur texture, ear shape, and facial features. These features often have non-linear relationships. A non-linear SVM with an appropriate kernel function can capture these relationships and effectively separate cat images from dog images.
The SVM Function
Finding this optimal hyperplane involves solving an optimization problem. The problem can be formulated as:
Minimize: 1/2 ||w||^2
Subject to: yi(w * xi + b) >= 1 for all i
Where:
w is the weight vector that defines the hyperplane
xi is the feature vector for data point i
yi is the class label for data point i (-1 or 1)
b is the bias term
This formulation aims to minimize the magnitude of the weight vector (which maximizes the margin) while ensuring that all data points are correctly classified with a margin of at least 1.
Data Assumptions
SVMs have few assumptions about the data:
- No Distributional Assumptions: - SVMs do not make strong assumptions about the underlying distribution of the data.
- Handles High Dimensionality: - They are effective in high-dimensional spaces, where the number of features is larger than the number of data points.
- Robust to Outliers: - SVMs are relatively robust to outliers, focusing on maximizing the margin rather than fitting all data points perfectly.
SVMs are powerful and versatile algorithms that have proven effective in various machine-learning tasks. Their ability to handle high-dimensional data and complex non-linear relationships makes them a valuable tool for solving challenging classification and regression problems.