Kappa
“Great things are not done by impulse, but by a series of small things brought together.”
Hack The Box
SARSA (State-Action-Reward-State-Action)
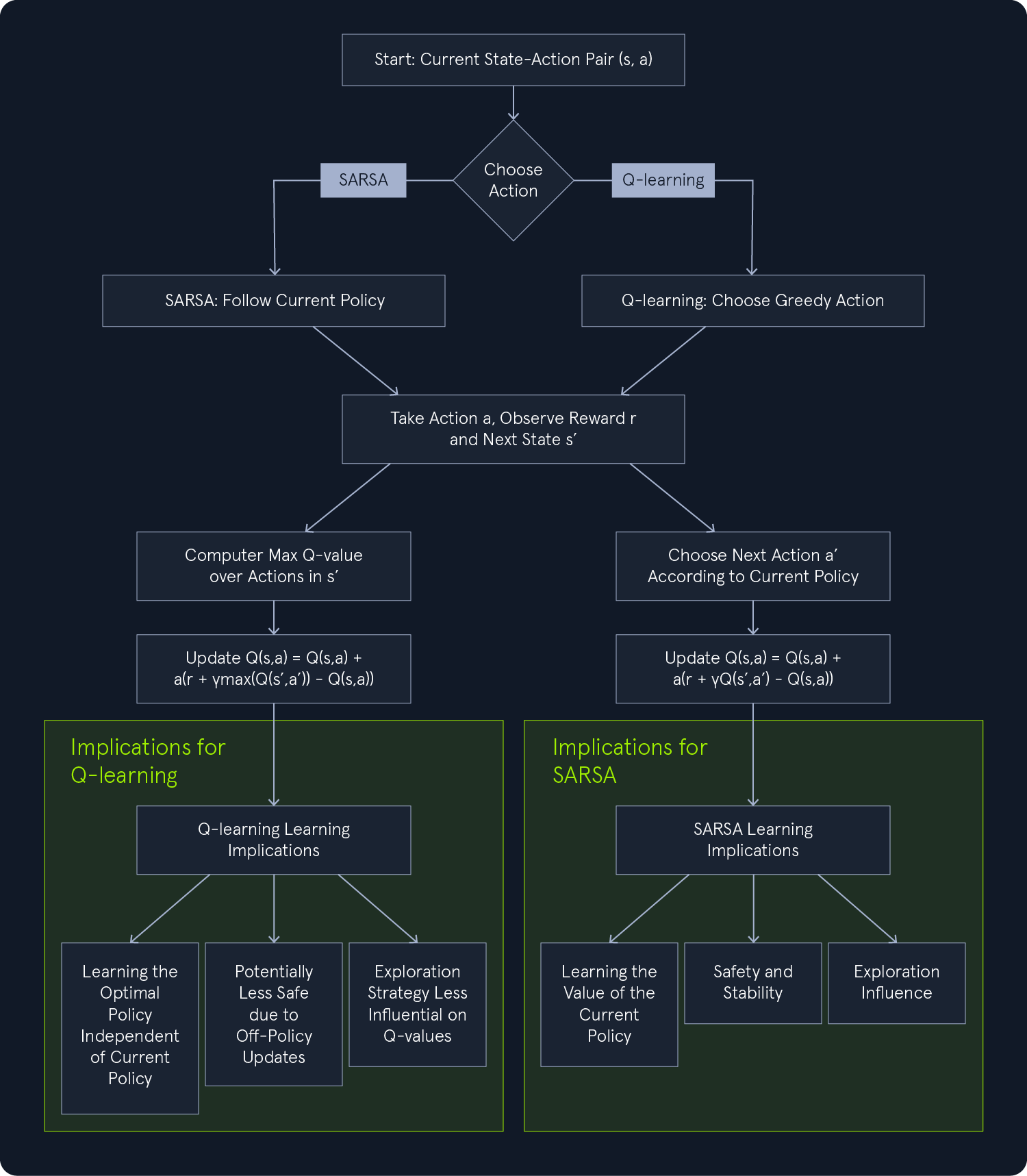
SARSA is a model-free reinforcement learning algorithm that learns an optimal policy through direct environmental interaction. Unlike Q-learning, which updates its Q-values based on the maximum Q-value of the next state, SARSA updates its Q-values based on the Q-value of the next state and the actual action taken in that state. This key difference makes SARSA an on-policy algorithm, meaning it learns the value of the policy it is currently following. Q-learning is off-policy, learning the value of the optimal policy independent of the current policy.
{kind=link}
The update rule for SARSA is:
Q(s, a) <- Q(s, a) + α * (r + γ * Q(s', a') - Q(s, a))
Here, s is the current state, a is the current action, r is the reward received, s' is the next state, a' is the next action taken, α is the learning rate, and γ is the discount factor. The term Q(s', a') reflects the expected future reward for the next state-action pair, which the current policy determines.
This conservative approach makes SARSA suitable for environments where policy needs to be followed closely. At the same time, Q-Learning's more exploratory nature can more efficiently find optimal policies in some cases.
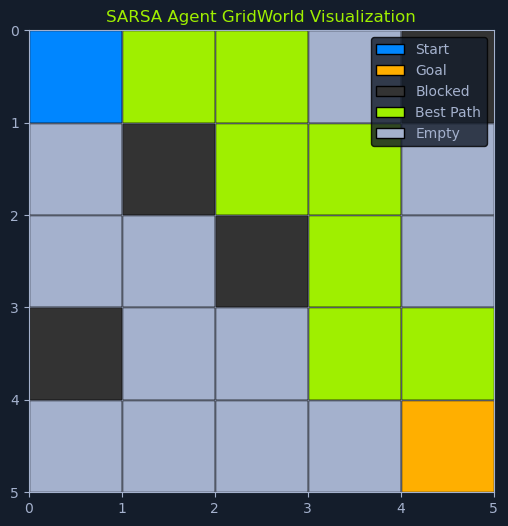
Imagine a robot learning to navigate a room with obstacles. SARSA guides the robot to learn a safe path by considering the immediate reward of an action and the consequences of the next action taken in the new state. This cautious approach helps the robot avoid risky actions that might lead to collisions, even if those actions initially seem promising.
The SARSA algorithm follows these steps:
- Initialization: - Initialize the Q-table with arbitrary values (usually 0) for each state-action pair. This table will store the estimated Q-values for actions in different states.
- Choose an Action: - In the current state s, select an action a to execute. This selection is typically based on an exploration-exploitation strategy, such as epsilon-greedy, balancing exploring new actions with exploiting actions known to yield high rewards.
- Take Action and Observe: - Execute the chosen action a in the environment and observe the next state s' and the reward r received. This step involves interacting with the environment and gathering feedback on the consequences of the action.
- Choose Next Action: - In the next state s', select the next action a' based on the current policy (e.g., epsilon-greedy). This step is crucial for SARSA's on-policy nature, considering the actual action taken in the next state, not just the theoretically optimal action.
- Update Q-value: - Update the Q-value for the state-action pair (s, a).
- Update State and Action: - Update the current state and action to the next state and action: s = s', a = a'. This prepares the algorithm for the next iteration.
- Iteration: - Repeat steps 2-6 until the Q-values converge or a maximum number of iterations is reached. This iterative process allows the agent to learn and refine its policy continuously.
On-Policy Learning
- https://academy.hackthebox.com/storage/modules/290/03%20-%20SARSA%20%28State-Action-Reward-State-Action%29_0.png
- https://academy.hackthebox.com/storage/modules/290/03%20-%20SARSA%20%28State-Action-Reward-State-Action%29_1.png
{kind=link}
{kind=link}
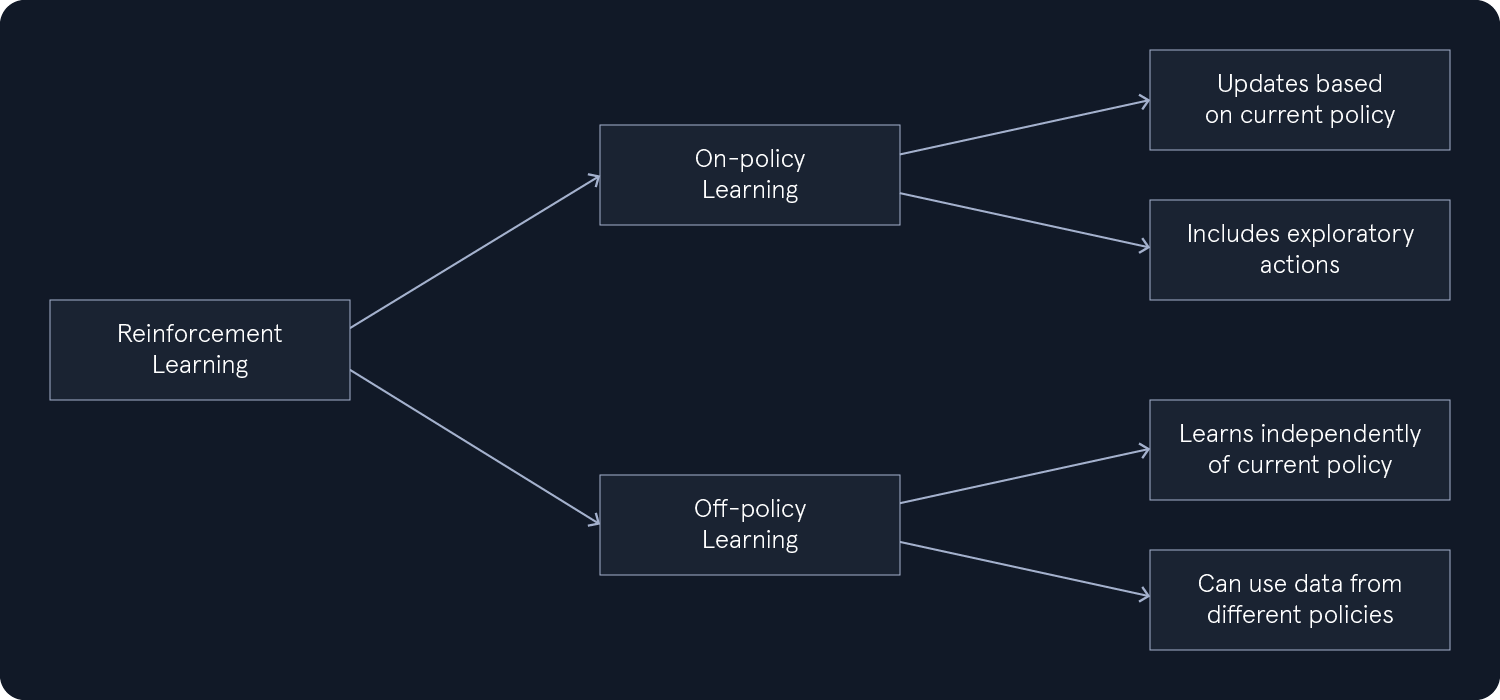
In reinforcement learning, the learning process can be categorized into two main approaches: on-policy and off-policy learning. This distinction stems from how algorithms update their estimates of action values, which are crucial for determining the optimal policy.
- On-policy learning: - In on-policy learning, the algorithm learns the value of its current policy. This means that the updates to the estimated action values are based on the actions taken and the rewards received while executing the current policy, including any exploratory actions.
- Off-policy learning: - In contrast, off-policy learning allows the algorithm to learn about an optimal policy independently of the policy being followed for action selection. This means the algorithm can learn from data generated by a different policy, which can benefit exploration and learning from historical data.
SARSA's on-policy nature stems from its unique update rule. It uses the Q-value of the next state and the actual action taken in that next state, according to the current policy, to update the Q-value of the current state-action pair. This contrasts with Q-learning, which uses the maximum Q-value over all possible actions in the next state, regardless of the current policy.
This distinction has important implications:
- Learning the Value of the Current Policy: - SARSA learns the value of its current policy, including the exploration steps. This means it estimates the expected return for taking actions according to the current policy, which might involve some exploratory moves.
- Safety and Stability: - On-policy learning can be advantageous in situations where safety and stability are critical. Since SARSA learns by following the current policy, it is less likely to explore potentially dangerous or unstable actions that could lead to negative consequences.
- Exploration Influence: - The exploration strategy (e.g., epsilon-greedy) influences learning. SARSA learns the policy's value, including exploration, so the learned Q-values reflect the balance between exploration and exploitation.
In essence, SARSA learns "on the job," continuously updating its estimates based on the actions taken and the rewards received while following its current policy. This makes it suitable for scenarios where learning a safe and stable policy is a priority, even if it means potentially sacrificing some optimality.
Exploration-Exploitation Strategies in SARSA
Just like Q-learning, SARSA also faces the exploration-exploitation dilemma. The agent must balance exploring new actions to discover potentially better strategies and exploiting its current knowledge to maximize rewards. The choice of exploration-exploitation strategy influences the learning process and the resulting policy.
Epsilon-Greedy
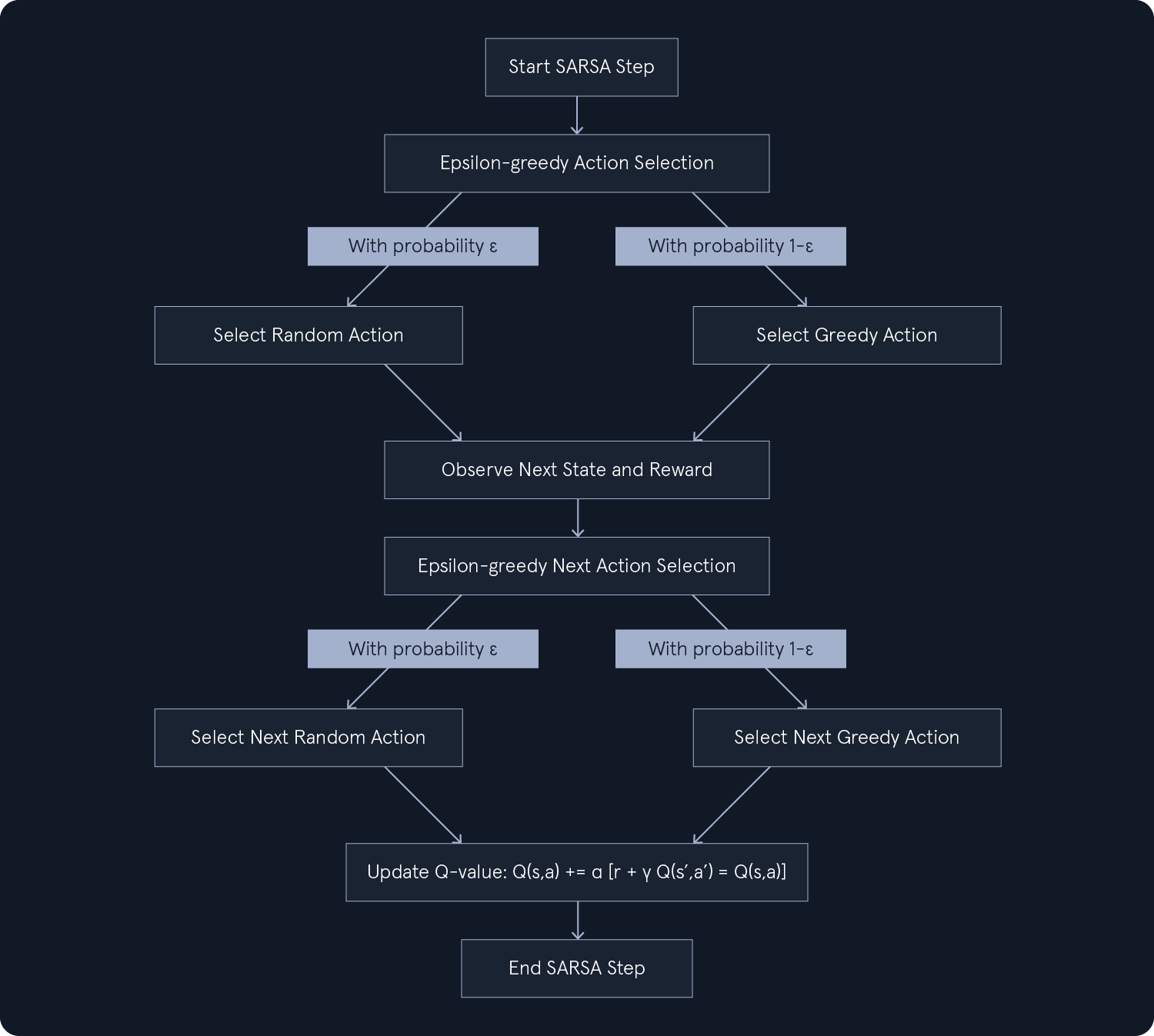
As discussed in Q-learning, the epsilon-greedy strategy involves selecting a random action with probability epsilon (ε) and the greedy action (highest Q-value) with probability 1-ε. This approach balances exploration and exploitation by occasionally choosing random actions to discover potentially better options.
{kind=link}
In SARSA, the epsilon-greedy strategy leads to more cautious exploration. The agent considers the potential consequences of exploratory actions in the next state, ensuring that they do not deviate too far from known good policies.
Softmax
The softmax strategy assigns probabilities to actions based on their Q-values, with higher Q-values leading to higher probabilities. This allows for a smoother exploration, where actions with moderately high Q-values still can be selected, promoting a more balanced approach to exploration and exploitation.
{kind=link}
In SARSA, the softmax strategy can lead to more nuanced and adaptive behavior. It encourages the agent to explore actions that are not necessarily the best but are still promising, thereby potentially leading to better long-term outcomes.
The choice of exploration-exploitation strategy in SARSA depends on the specific problem and the desired balance between safety and optimality. A more exploratory strategy might lead to a longer learning process but potentially a more optimal policy. A more conservative strategy might lead to faster learning but potentially a suboptimal policy that avoids risky actions.
Convergence and Parameter Tuning
Like other iterative algorithms, SARSA requires careful parameter tuning to ensure convergence to an optimal policy. Convergence in Reinforcement Learning means the algorithm reaches a stable solution where the Q-values no longer change significantly with further training. This indicates that the agent has learned a policy that effectively maximizes rewards.
Two crucial parameters that influence the learning process are the learning rate (α) and the discount factor (γ):
- Learning Rate (α): - Controls the extent of Q-value updates in each iteration. A high α leads to faster updates but can cause instability, while a low α ensures more stable convergence but slows down learning.
- Discount Factor (γ): - Determines the importance of future rewards relative to immediate rewards. A high γ (close to 1) emphasizes long-term rewards, while a low γ prioritizes immediate rewards.
Tuning these parameters often involves experimentation to find a balance that ensures stable and efficient learning. Techniques like grid search or cross-validation can systematically explore different parameter combinations to identify optimal settings for a given problem.
The convergence of SARSA also depends on the exploration-exploitation strategy and the nature of the environment. SARSA is guaranteed to converge to an optimal policy under certain conditions, such as when the learning rate is sufficiently small, and the exploration strategy ensures that all state-action pairs are visited infinitely often.
Data Assumptions
SARSA makes similar assumptions to Q-learning:
- Markov Property: - It assumes that the environment satisfies the Markov property, meaning that the next state depends only on the current state and action, not on the history of previous states and actions.
- Stationary Environment: - It assumes that the environment's dynamics (transition probabilities and reward functions) do not change over time.
SARSA is a valuable reinforcement learning algorithm that offers an on-policy learning approach, making it suitable for scenarios where safety and stability are critical considerations. Its ability to learn by following a specific policy allows it to find effective solutions while avoiding potentially harmful actions.
Fundamentals of AI
- Introduction to Machine Learning
- Mathematics Refresher for AI
- Supervised Learning Algorithms
- Linear Regression
- Logistic Regression
- Decision Trees
- Naive Bayes
- Support Vector Machines (SVMs)
- Unsupervised Learning Algorithms
- K-Means Clustering
- Principal Component Analysis (PCA)
- Anomaly Detection
- Reinforcement Learning Algorithms
- Q-Learning
- ~ SARSA (State-Action-Reward-State-Action)
- Introduction to Deep Learning