Kappa
“Great things are not done by impulse, but by a series of small things brought together.”
Hack The Box
Perceptrons
The perceptron is a fundamental building block of neural networks. It is a simplified model of a biological neuron that can make basic decisions. Understanding perceptrons is crucial for grasping the concepts behind more complex neural networks used in deep learning.
{kind=link}
Structure of a Perceptron
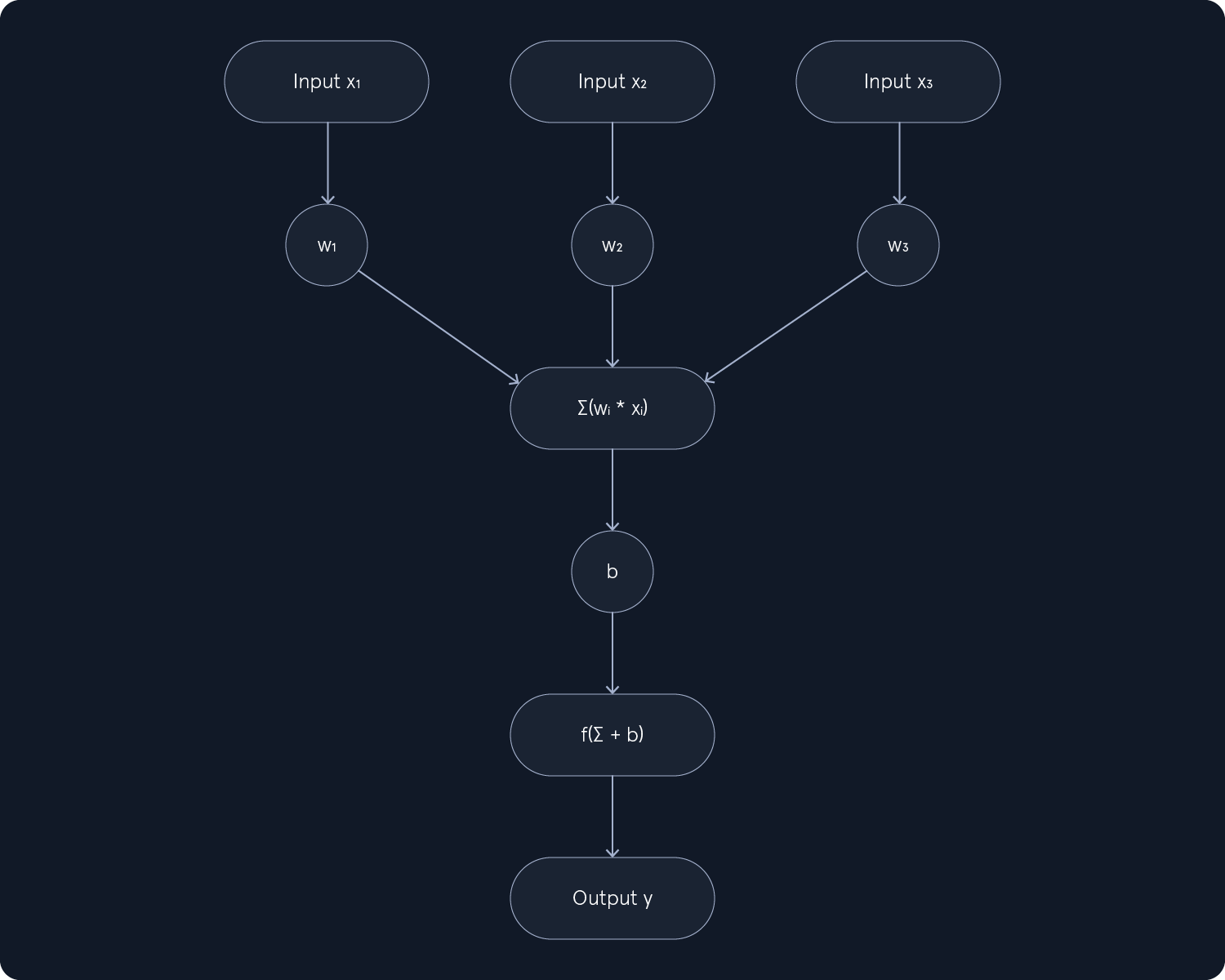
A perceptron consists of the following components:
- Input Values (x1, x2, ..., xn): - These are the initial data points fed into the perceptron. Each input value represents a feature or attribute of the data.
- Weights (w1, w2, ..., wn): - Each input value is associated with a weight, determining its strength or importance. Weights can be positive or negative and influence the output of the perceptron.
- Summation Function (∑): - The weighted inputs are summed together as ∑(wi * xi) . This step aggregates the weighted inputs into a single value.
- Bias (b): - A bias term is added to the weighted sum to shift the activation function. It allows the perceptron to activate even when all inputs are zero.
- Activation Function (f): - The activation function introduces non-linearity into the perceptron. It takes the weighted sum plus the bias as input and produces an output based on a predefined threshold.
- Output (y): - The final output of the perceptron, typically a binary value (0 or 1) representing a decision or classification.
In essence, a perceptron takes a set of inputs, multiplies them by their corresponding weights, sums them up, adds a bias, and then applies an activation function to produce an output. This simple yet powerful structure forms the basis of more complex neural networks used in deep learning.
Deciding to Play Tennis
Let's illustrate the functionality of a perceptron with a simple example: deciding whether to play tennis based on weather conditions. We'll consider four input features:
- Outlook: - Sunny (0), Overcast (1), Rainy (2)
- Temperature: - Hot (0), Mild (1), Cool (2)
- Humidity: - High (0), Normal (1)
- Wind: - Weak (0), Strong (1)
Our perceptron will take these inputs and output a binary decision: Play Tennis (1) or Don't Play Tennis (0).
For simplicity, let's assume the following weights and bias:
- w1 (Outlook) = 0.3
- w2 (Temperature) = 0.2
- w3 (Humidity) = -0.4
- w4 (Wind) = -0.2
- b (Bias) = 0.1
We'll use a simple step activation function:
f(x) = 1 if x > 0, else 0
Implemented in Python, like this:
def step_activation(x):
"""Step activation function."""
return 1 if x > 0 else 0
Now, let's consider a day with the following conditions:
- Outlook: Sunny (0)
- Temperature: Mild (1)
- Humidity: High (0)
- Wind: Weak (0)
The perceptron calculates the weighted sum:
(0.3 * 0) + (0.2 * 1) + (-0.4 * 0) + (-0.2 * 0) = 0.2
Adding the bias:
0.2 + 0.1 = 0.3
Applying the activation function:
f(0.3) = 1 (since 0.3 > 0)
The output is 1, so the perceptron decides to Play Tennis.
In Python, this looks like this:
# Input features
outlook = 0
temperature = 1
humidity = 0
wind = 0
# Weights and bias
w1 = 0.3
w2 = 0.2
w3 = -0.4
w4 = -0.2
b = 0.1
# Calculate weighted sum
weighted_sum = (w1 * outlook) + (w2 * temperature) + (w3 * humidity) + (w4 * wind)
# Add bias
total_input = weighted_sum + b
# Apply activation function
output = step_activation(total_input)
print(f"Output: {output}") # Output: 1 (Play Tennis)
This basic example demonstrates how a perceptron can weigh different inputs and make a binary decision based on a simple activation function. In real-world scenarios, perceptrons are often combined into complex networks to solve more intricate tasks.
The Limitations of Perceptrons
While perceptrons provide a foundational understanding of neural networks, single-layer perceptrons have significant limitations that restrict their applicability to more complex tasks.
The most notable limitation is their inability to solve problems that are not linearly separable. A dataset is considered linearly separable if it can be divided into two classes by a single straight line (or hyperplane in higher dimensions). Single-layer perceptrons can only learn linear decision boundaries, making them incapable of classifying data with non-linear patterns.
A classic example is the XOR problem. The XOR function returns true (1) if only one of the inputs is true and false (0) otherwise. It's impossible to draw a single straight line that separates the true and false outputs of the XOR function. This limitation severely restricts the types of problems a single-layer perceptron can solve.
Fundamentals of AI
- Introduction to Machine Learning
- Mathematics Refresher for AI
- Supervised Learning Algorithms
- Linear Regression
- Logistic Regression
- Decision Trees
- Naive Bayes
- Support Vector Machines (SVMs)
- Unsupervised Learning Algorithms
- K-Means Clustering
- Principal Component Analysis (PCA)
- Anomaly Detection
- Reinforcement Learning Algorithms
- Q-Learning
- SARSA (State-Action-Reward-State-Action)
- Introduction to Deep Learning
- ~ Perceptrons
- Neural Networks